1960년대부터 1990년대까지 정부에서 주로 사용되었던 타자기록을 쉽고 간편하게 검색하고 활용할 수 있게 된다.
국가기록원은 딥러닝 기반으로 약 22만 개의 한글 타자체 단어를 학습시켜 국내 최초로 비전자 타자기록의 인공지능(AI) 문자인식(OCR) 기술 개발에 성공하였다고 밝혔다.
사람이 쓰거나 기계로 인쇄한 문자의 이미지를 기계가 읽을 수 있는 문자로 변환하는 기술
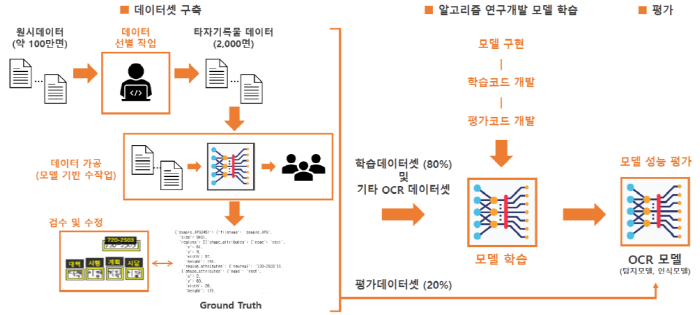
이러한 기술은 국가기록원이 ‘20년 연구개발 사업의 일환으로 인공지능 스타트업 기업과 협업하여 수행한 「소장기록물 특성을 고려한 OCR 인식 성능 개선방안 연구」 과제를 통해 개발되었다.
국가기록원은 그동안 문서를 이미지로 스캔한 파일을 제공해왔으나, 문서내용 검색에는 한계가 있어 이용자들의 불편이 있었다.
특히 기존의 문자인식 기술은 활자체에 최적화되어 있어, 사람이 손으로 쓰거나 타자를 이용하여 작성된 문서의 경우에는 효과가 크지 않았다.
타자기록은 1950년대에 최초로 세벌식 타자기가 양산되면서 정부의 공문서 작성에 쓰이기 시작했으며, 1969년에 네벌식, 1982년에 두벌식 자판이 사용되는 등 글꼴이 매우 다양하고 시각적으로 활자체와 차이가 있어 기존의 기술로는 인식성능이 떨어진다.
이번 개발에 사용된 학습데이터는 1960~1990년대까지 재무부, 외무부, 건설교통부 등에서 생산한 도시계획, 경제계획 문서와 국무회의, 경제장관회의 등의 회의록 및 각종 법령 등을 대상으로 하고 있다.
올해는 1단계로 공공기관에서 컴퓨터가 보급되기 이전에 주로 사용해 왔던 타자기록에 대해 문자인식 연구를 추진했다.
그 결과, 기존의 문자인식 기술과는 달리 문자탐지와 문자인식의 2단계로 구성된 딥러닝 기반의 인공지능 문자인식 모델을 개발하여 학습 속도를 개선하고 인식성능을 90% 이상 획기적으로 높였다.
앞으로 국가기록원은 문자인식 기술을 적용·발전시켜 국민들이 보다 쉽고 편리하게 기록물을 활용할 수 있도록 비전자 기록물의 원문 검색 및 색인 등의 정보 활용 서비스에 확대 적용할 계획이다.
아울러, 이번에 구축된 학습데이터는 국가기록원 누리집을 통해 공개될 예정이다.
안경원 국가기록원장 직무대리는 “이번 연구를 통해 개발된 기술은 국가기록원의 기록물 접근성 향상에 기여했다는 점에서 큰 의미가 있다.”며 “국가기록원은 앞으로도 인공지능 기술 등의 접목을 통해 국민들이 필요한 서비스를 제공할 수 있도록 노력하겠다.”라고 밝혔다.
이창희 기자 <저작권자 ⓒ 헤드라인코리아저널 무단전재 및 재배포금지>






